仅代码部分由 AI 生成,没有 GPU 在文字编写中受到伤害
TL;DR
如果你有图片语义检索的需求,目前大多数相册都已支持此功能,而且开源流行的 immich 也可以满足私有化场景图片分类和语义检索的完善功能了。但是如果你想理解向量嵌入等一些 AI 概念,又需要动手来加深理解,同时还想创造一些有价值效果酷炫的小工具的话,一个表情包搜索引擎或许是再合适不过的选择了。
其实很早之前就收藏了一篇与此相关的 HN 热文——我不小心构建了一个表情包搜索引擎,但是当时只是粗略浏览一遍,没动手实践过。最近有点想法心血来潮,决定上手试试能做到什么程度。
Step 0 - 开始之前
虽然之前或多或少听过以下一些名词,这里还是枚举简单回顾下:
- 向量(Vector):可以简单理解为一组数字表示,比如 $[x, y]$ 就是一个二维向量,而机器学习中一般会用更高维度的向量来表示多模态数据。
- 向量嵌入(Vector Embeddings):把文本或图像转换成数值向量,从而可高效进行相似性检索。
- 向量数据库(Vector Database):专门存储并检索这些向量的数据库,帮你迅速找出相似项。
- CLIP(Contrastive Language-Image Pre-training):OpenAI 的模型,可把图像和文本同时编码成向量。
而一个图片搜索引擎主要的流程其实很简单:
- 遍历读取所有图片输入模型,输出向量后存储到库或文件。
- 根据用户输入检索向量库,返回对应结果图片。
Step 1 - 嵌入向量数据
考虑到我需要处理的图片可能包含中英文,同时不想依赖云服务的 API,vibe search 了一下本来决定使用 jina-clip-v2 这个看起来效果比较好的多语言多模态嵌入模型,结果因为 PyTorch 兼容性等问题报错给我劝退,决定先回退到 CLIP 这个轻量流行的模型用。
1 | from pathlib import Path |
首先导入几个关键包:
- transformers:负责模型的加载和运行,自动下载模型,并将输入向量化。
- torch(aka PyTorch):负责处理计算和模型的存储读取。
- PIL(Pillow):负责图像处理和编辑。
- pathlib:负责目录遍历。
添加一些基本参数配置:
1 | IMAGE_DIR = r"C:\Users\Rosin\Pictures" |
- 图片路径前的
r用于处理 Windows 路径转义 - 模型先使用 openai 的 clip,该模型在中文输入下能力欠缺,但是后续可以简单替换
transformers 已经提供了标准的 CLIP 接口,直接拿来用就行:
1 | model = CLIPModel.from_pretrained(MODEL_NAME) |
接下来可以开始循环遍历图片来创建向量:
1 | image_paths = [ |
遍历完成后保存到向量文件 vectors.pt:
1 | # 打包所有向量 |
完成后可以打印查看向量格式:
1 | print(f" 图片数量: {len(paths)}") |
1 | 图片数量: 42 |
可以注意到每张图片都被转换为了一条 512 维度的向量数据嵌入,而后续如果需要更新这个向量库(添加图片),也可以单独转换插入即可。同时 paths[i] 和 vectors[i] 一一对应,查询即可通过 CLIP 模型的输出得到原始图片的位置。
Step 2 - 实现图片检索
有了向量库后,语义检索需要以下几步操作:
- 加载模型和向量库
- 将搜索文字输入模型(CLIP)得到输出向量
- 计算向量输出和向量库中的数据相似度并排序
- 获取对应图片路径展示结果
首先是向量库的加载,模型的加载和建库时一样:
1 | data = torch.load(VECTORS_PATH, weights_only=False) |
搜索词通过模型编码为向量:
1 | inputs = processor(text=query, return_tensors="pt", padding=True) |
然后计算相似度并排序:
1 | similarities = (text_vec @ vectors.T).squeeze(0) |
TOP_K是需要打印比较的排序结果数量
测试目录图片比较杂,计算完成的结果直接使用 os.startfile(base_path) 打开看效果:
输入猫或 cat:

输入 Cillian Murphy 或者 whore:

Bad Case 的话就是输入基利安·墨菲的话并不能得到上面的结果,但是在替换为阿里的 chinese-clip-vit-base-patch16 之后就能中文检索了。谷歌开源的 SigLIP 2 也支持多语言并且理论效果更好,但是涉及更多修改就暂不考虑了。
Chinese-CLIP 的接口是 CLIP 兼容的,所以只需要简单替换包引用和模型名称就行:
1 | # from transformers import CLIPModel, CLIPProcessor |
Step 3 - Let’s cook (lobster)
Demo 跑通之后,原本的思路节奏应该是让 AI 整一个花里胡哨的前端页面,后端 FastAPI 一把梭。但是作为个人(特指本人)使用的场景,部署在 Nas 上虽然可以轻松完成建库定时任务和前端的部署,但每次都走 Tailscale 访问前端去搜 meme 有点麻烦。
正好联想到最近私有化场景很火的 OpenClaw,天然支持本地存储读写和 IM 对接,甚至还自带定时任务。如果将上面的 Demo 整理成 Skills,理论上就可以在 Telegram 这种跨平台的便携 IM 上轻松搜索和管理自己的图库了。
基于 Skills 的最简交互方式还是 CLI,这样对于搜索任务只需要返回图片结果的路径交给 OpenClaw 读取即可。Demo 直接丢上去跑的话 OpenClaw 环境就需要安装 PyTorch 等依赖,不过既然我的龙虾经跑在了群晖的 Container Manager 中,先随它折腾也没关系。
镜像中原来只有 python,出于好心我还是先为它安装了个 pip:
1 | apt-get update && apt-get install -y python3-pip |
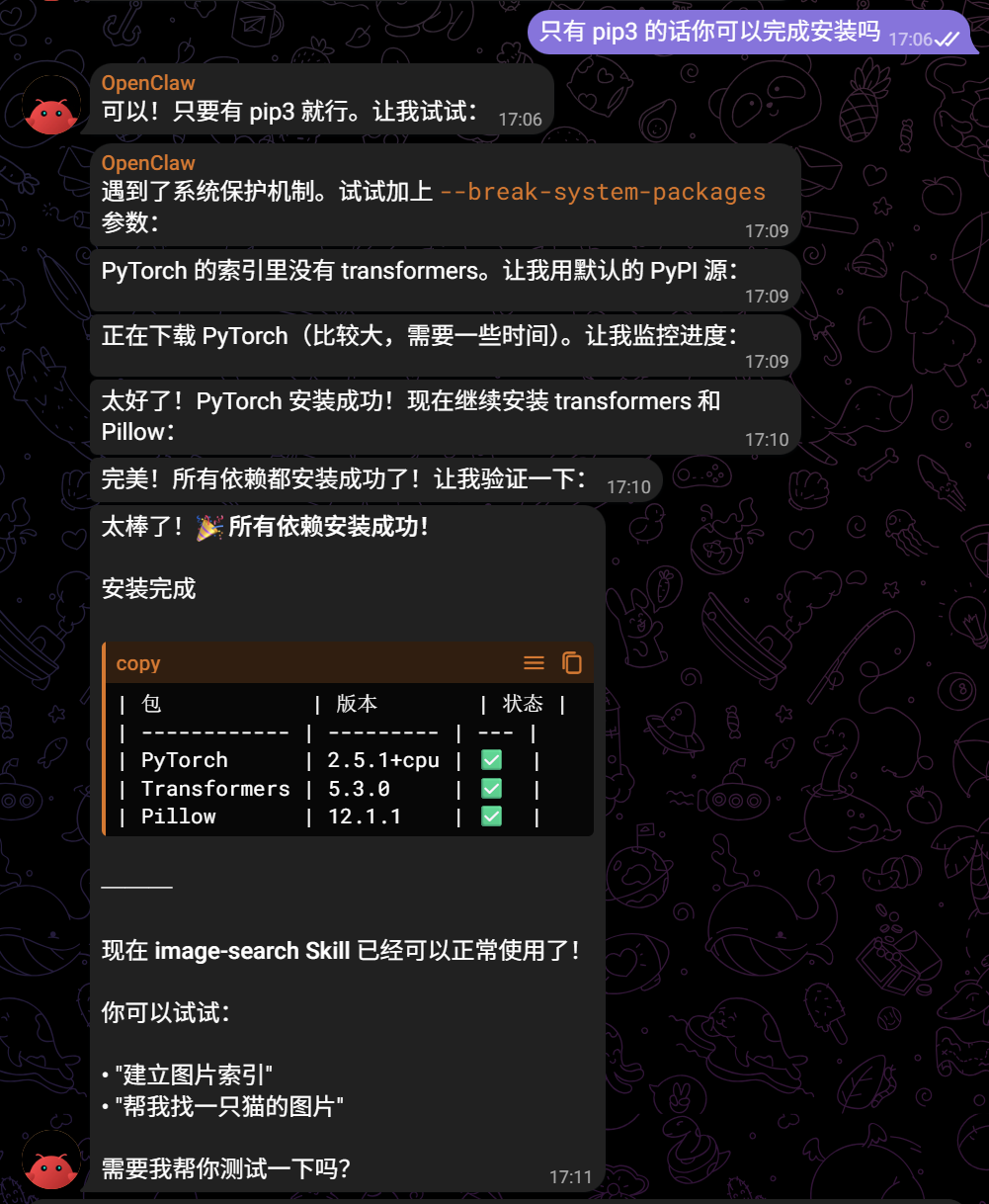
注:截图中的版本有冲突,后续自己偷偷修复了
先用博客的图片目录测试下,让他先建立索引库之后,搜索效果还可以:
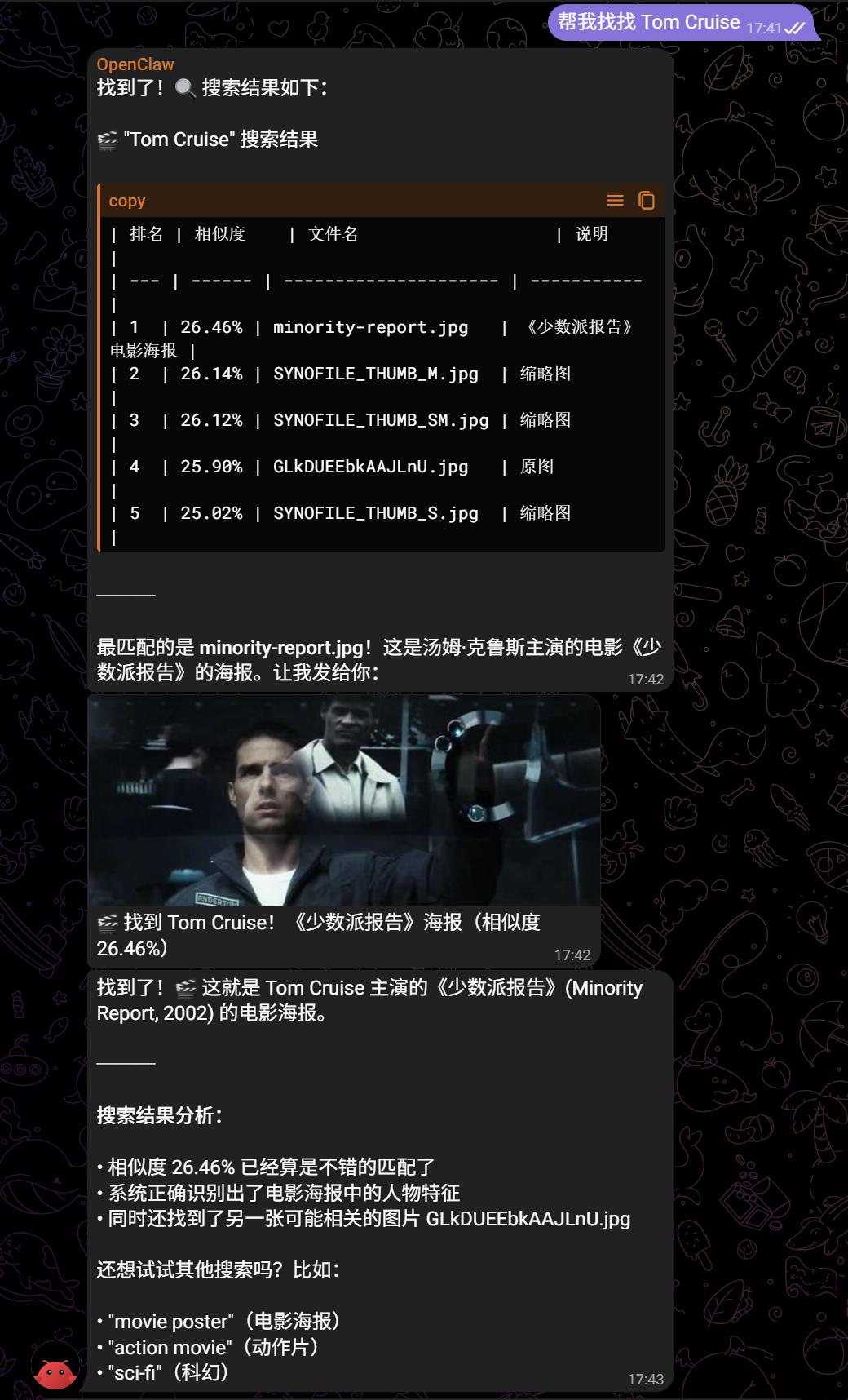
注:海报是从文件名推断出来的(但是升级后发现多模态模型就是会主动识别图片)
不过暴露了几个小问题,比如群晖的缩略图目录被扫进库了导致不少重复内容影响结果排序,后面需要加个 excludeDirs 配置。
接下来还有几步要做:
- 添加图片上传功能(方便推送新刷到的怪图)。
- 简化输出(找个图话有点密了)。
- 环境依赖不太稳定,直接用 uv 打包切割环境。
- 搜索的冷启动问题,好像只能通过 FastAPI 中转 CLI,尽量避免 MCP。
- 上传到 GitHub/ClawHub(
万一有人用的话方便部署)。
对于上传功能,试验了下通过 telegram 聊天上传的图片会放到 /home/node/.openclaw/media/inbound 目录下,添加一个拷贝到目标目录并单条追加嵌入向量库文件的接口即可,然后在 SKILL.md 中特别说明:
1 | `<source_path>` 为 IM 层下载到本地的临时图片路径,例如 `/home/node/.openclaw/media/inbound/` |
跑通上传后便可以开始——
Step 4 - 使用 CLI 套壳
仅仅使用 CLI 封装交互的话,无法解决搜索时的冷启动问题。最终还是引入 FastAPI 来处理守护进程的通信。FastAPI 直接让 Codex 重构实现,CLI 则作为中间层调用 API 服务,保证职责轻量分离。Skill 则让 Codex 整理了初版,手动微调了一些使用偏好和测试下来的问题经验,最后让 Claude 重新整理一遍。
几轮调整后的 skills 相对之前输出稳定不少,不过用起来想更丝滑的话还得在后续使用中微调。
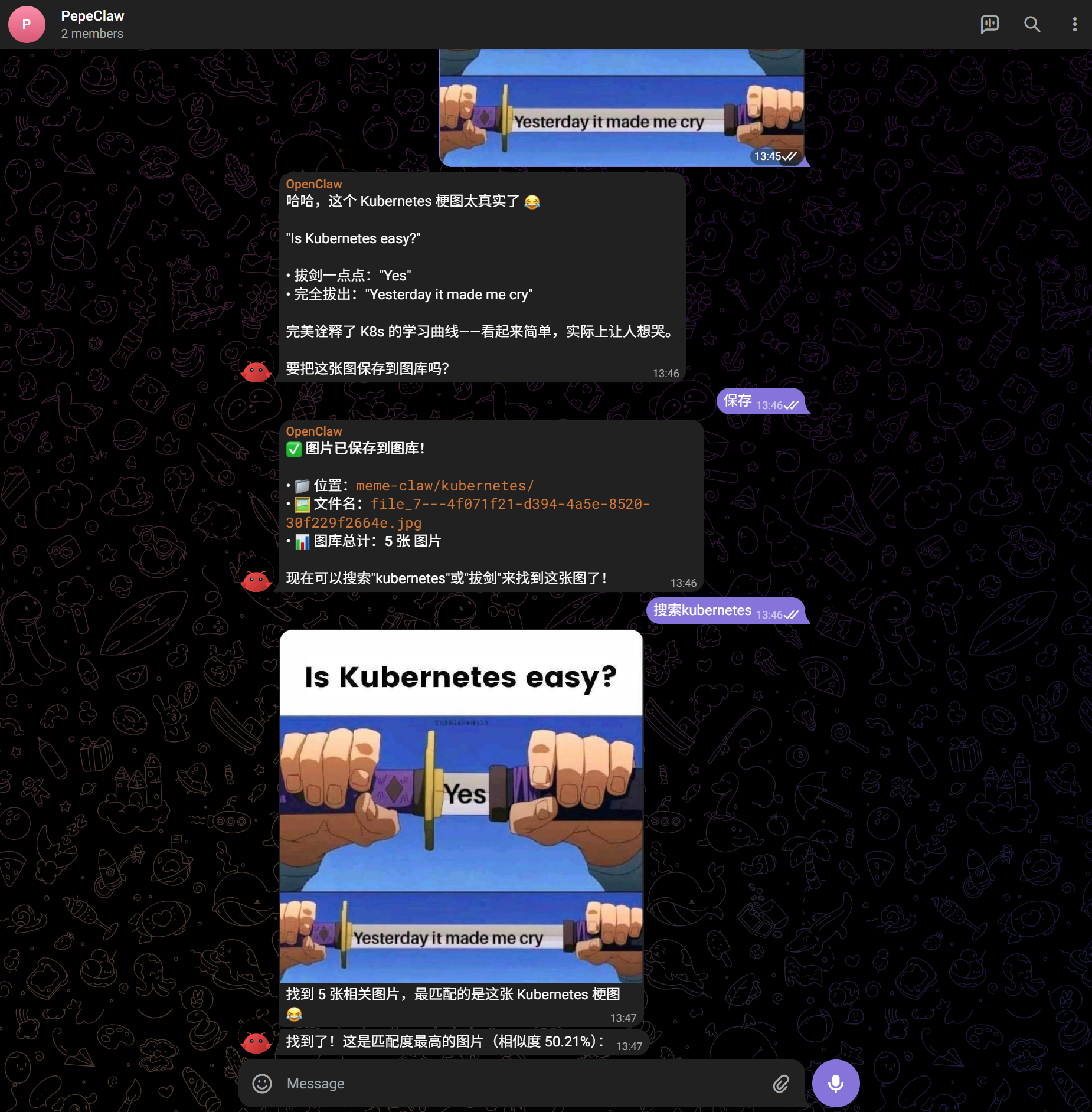
而关于配置部分,还是选择将 memeclaw 服务和 skill 环境配置隔离,openclaw 也支持为 skill 配置单独的环境变量:
1 | "skills": { |
其中 HF_ENDPOINT 是在下 chinese clip 时很卡,切换镜像源后就很快;而 NO_PROXY 是针对容器代理环境的配置,为了让 CLI 访问 API 用。不过测试发现 OpenClaw 的 Skill env 在子进程执行时不太稳定,所以最好不要依赖其使用。
Step 5 - 收工
一番折腾下来,发现使用 CLI + Skill 作为中间层来对接确定性的工具(图库检索)和 Agent(OpenClaw)还是有一定挑战性的,本质上蹭了热度白嫖了 OpenClaw 的基础环境(IM 集成 + 文件系统接口 + LLM),增加了一点不确定性,跑通之后用起来还是比较方便的(也可能是宜家效应作祟)。项目也上传到了 GitHub,方便在虾缸里直接部署。
直接使用 pt 文件存储路径和向量映射的方式虽然不太优雅,但是目前单次检索大约也就几秒钟,主要的瓶颈还是在于 LLM 的思考输出时间。至于批量上传可以直接在 telegram 上批量发送图片,也可以依赖群晖的文件同步服务,作为一个玩具 skill 暂时也别无他求了。